题目一:

有2堆宝石,A和B一起玩游戏,假设俩人足够聪明,规则是每个人只能从一堆选走1个或2个或3个宝石,最后全部取玩的人获胜,假设2堆宝石的数目为12和13,请问A怎么可以必胜?
让A先取
让B先取
没有策略能够让A必胜
说法都不正确
答案:
A只要取完宝石后给B留4的倍数就能赢,留下4的倍数,B就没有办法取完。而A每次都可以按照B取的数量来修正,保证每次留给B的是4的倍数。到最后B没有办法一次取完4个,而且必须要取,剩下的A取完就赢了。
题目二:
从数字集合{1,2,3,4,… ,20}中选出3个数字的子集,如果不允许两个相连的数字出现在同一集合中,那么能够形成多少个这种子集?
220
340
620
这道题可以理解为把3本书插到17本书的中间,即加头尾的18个空格里,有多少种组合。因为不能相邻,所以是有C 18 3=816 种方法。
补充1:
从数字集合{1,2,3,4,… ,20}中选出4个数字的子集,如果不允许两个相连的数字出现在同一集合中,那么能够形成多少个这种子集?
2380
330
1220
直接思路:不相邻问题其实就是插空问题,题目要求四个元素中不存在相邻元素,相当于将这四个数插入剩余16个数形成的空格中,
12_3_4_5_6_7..._18_19_20_,其实每将这四个数插入这些空格中,就能形成一个不存在相邻元素的四个元素集合,也就是说插空和
构成一个元素是对应的,一种插空结果对应一个不相邻的四个元素集合,所以答案为: C(17,4)=2380.
2:
采用插隔板法,即8灯关3,余5灯亮,5灯之间6个空,插入3盏不亮灯答案:C(6,3)商品名称
题目三:
某销售车辆公司某一时间段各类商品的销售量如下图,
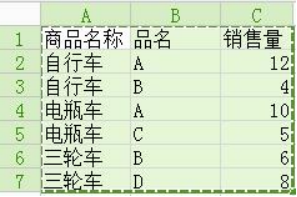
销售员需统计以下公式所示数据=SUM(SUMIF(C2:C9,{"<10","<6"})*{1,-1})
请问,该公式返回值为
SUMIF(C2:C7,{"<10","<6"})返回{23,9},分别对C2:C7中<10、<6的数据进行求和,即SUM(4,5,6,8),SUM(4,5),结果为{23,9}
SUM(SUMIF(C2:C7,{"<10","<6"})*{1,-1})经过上一步,转为SUM({23,9}*{1,-1}),即23-9=14。
题目五:
设随机变量X和Y都服从正态分布,且它们不相关,则( )
A.只有当(X,Y) 服从二维正态分布时,X与Y不相关⇔X与Y独立,本题仅仅已知X和Y服从正态分布,因此,由它们不相关推不出X与Y一定独立,故A错误;
B.若X和Y都服从正态分布且相互独立,则(X,Y)服从二维正态分布,但题设并不知道X,Y是否独立,故B错误;
C.由A、B分析可知X与Y未必独立,故C正确;
D.需要求X与Y相互独立时,才能推出X+Y服从一维正态分布,故D错误.
故选:C
题目六:
有 10 粒糖,如果每天至少吃一粒(多不限),吃完为止,求有多少种不同吃法?( )
144
217
512
640
正确答案:C
将10粒糖并列一排放置,中间形成9个空位,在这9个空位中任意插入0-9个隔板,(即表示10粒糖在1到10天吃完),故共有C(0,9)+C(1,9)+C(2,9)+...+C(9,9) = 512,答案选择C
m个正整数之和为n求一共有多少种方法?(有序,即1+2=3和2+1=3不同)结果为C(m-1,n-1)对于本题m为一个范围1-10,n为10,带入也可得到512。
题目七:
对于任意事件A、B,有如下( )成立
题目八:
以下哪些数据可以评估用户黏性?()
题目九:
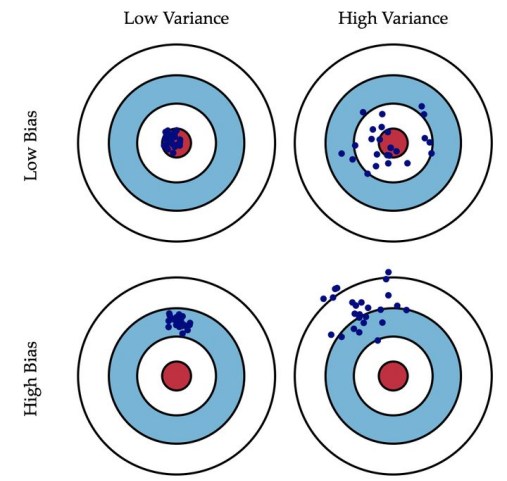
评估模型之后得出模型存在偏差,下列哪种方法可能解决这一问题?()
过拟合 高方差 低偏差 欠拟合 低方差 高偏差 ,
高偏差意味模型不够复杂(欠拟合),为了模型更加的强大,我们需要向特征空间中增加特征。增加样本能够降低方差
以下哪个模型是生成式模型:
判别式模型:直接对条件概率p(y|x)进行建模,常见判别模型有:线性回归、逻辑回归,决策树、支持向量机SVM、k近邻、神经网络,条件随机场等;
生成式模型(Generative Model):对联合分布概率p(x,y)进行建模,常见生成式模型有:隐马尔可夫模型HMM、朴素贝叶斯模型、高斯混合模型GMM、线性判别分析LDA等;
生成式模型更普适;判别式模型更直接,目标性更强
生成式模型关注数据是如何产生的,寻找的是数据分布模型;判别式模型关注的数据的差异性,寻找的是分类面,由生成式模型可以产生判别式模型,但是由判别式模式没法形成生成式模型
题目十:
以下哪些方法不可以直接来对文本分类?
题目十一:
在某神经网络的隐层输出中,包含0.75,那么该神经网络采用的激活函数可能是()
题目十二:
下列关于决策树的说法正确的是( )
题目十三:
下列属于无监督学习的模型是:()
题目十四:
以下哪些模型是分类模型:()
题目十五:
请输入正确的vlookup公式查询当前用户id的性别()
VLOOKUP(要查找的值,查找的区域,查找区域返回的列,查找模式)
第4个参数,查找模式:0表示精确匹配,1表示模糊匹配
题目十六:
0到1000当中有多少个数字带有1 ()
不包含1的数字有9的3次方=729个,所以包含1的数字有1001-729=272个。
题目十七:
在EXCEL输入以零开头的文本型数字时需在输入的数据前面加( )
题目十八:
常用的最优模型选择方法是哪些?()
模型选择就是选择在未知数据集上预测性能较好的模型,两种常用的模型选择方法:正则化与交叉验证。
正则化是结构风险最小化策略的实现,实在经验风险上加一个正则化项或罚项。正则化项一般是模型复杂度的单调递增函数,模型复杂度越大,正则化值就越大。
有效性。以统计量估计总体参数时,优良估计量的方差应该比其他估计量的方差小。
题目二十:
主要的时间序列因素有以下四种:
(1)长期趋势。它是事物在长时期内增减的变动趋势。
(2)季节变动。是在每期内重复出现的周期性变动。一般季节变动周期为12个月。通常农产品的季节变动大于工业产品,销费品大于生产资料,非耐用品大于耐用品。
(3)循环变动。它是以期数为周期而重复出现的周期性变动。由于这种周期性变动的周期长短不规律,预测方法也无规律可循。一般在短期预测中把循环变动因素当作长期趋势的一部分,不单独分析。
(4)不规则变动。指由各种复杂因素引起的,在时间序列曲线上形成很多微小波动性变动。这种变动也无规律可循,难以预测分析,在时间序列中,通常是采用移动平均法或指数平滑法,以消除被动的干扰。
题目二十一:
设A B C为三件事件,且A B 相互独立,则以下结论中不正确的是()
题目二十二:
假设出现在小红书首页的笔记,三十次曝光至少会被点开一次的概率是0.95,请问,十次曝光被点开的概率是多少()
“30次曝光至少点击一次的概率为0.95”
30次曝光,每次曝光是否点击都是独立事件,故做了30次独立事件。则30次曝光都没有点击的概率是0.05
设每次点击的概率为a,则有(1-a)^30=0.05
问:10次曝光至少点击1次的概率是多少?
即求{1-(1-a)^10}
(1-a)^10 ={(1-a)^30}^(1/3)=0.5^(1/3) 计算可知0.4^3=0.064>0.5 0.3^3 = 0.027<0.5
故 0.3<(1-a)^10 <0.4, 0.6< 1-(1-a)^10 <0.7 选A
题目二十三:
只访问了入口页面(例如首页)就离开的访问量与所产生总访问量的百分比是()
跳出率是指在只访问了入口页面(例如网站首页)就离开的访问量与所产生总访问量的百分比。跳出率计算公式:跳出率=访问一个页面后离开网站的次数/总访问次数;
访问率(reach)是有多少不同的人参观访问一个网站查看广告以及这些人们成为一个广告瞄准的对象的百分比。
转化率=(产生购买行为的客户人数/所有到达店铺的访客人数)×100%。
流失率=流失人数/总人数
题目二十四:
AARRR模型不包含以下哪个环节?()
Acquisition 获取用户
Activation 提高活跃度
Retention 提高留存率
Revenue 获取收入
Refer 自传播
补充:
1.AARRR模型分别对应用户生命周期中的每个阶段。以下不属于某个阶段的是
AARRR是Acquisition、Activation、Retention、Revenue、Referral,五个单词的缩写,分别对应用户生命周期中的5个。
以下以移动应用为例简单讲解AARRR模型每个阶段。
用户获取(Acquisition)
运营一款移动应用的第一步,毫无疑问是获取用户,也就是大家通常所说的推广。如果没有用户,就谈不上运营。
用户激活(Activation)
很多用户可能是通过终端预置(刷机)、广告等不同的渠道进入应用的,这些用户是被动地进入应用的。如何把他们转化为活跃用户,是运营者面临的第一个问题。
当然,这里面一个重要的因素是推广渠道的质量。差的推广渠道带来的是大量的一次性用户。好的推广渠道往往是有针对性地圈定了目标人群,他们带来的用户和应用设计时设定的目标人群有很大吻合度,这样的用户通常比较容易成为活跃用户。挑选推广渠道的时候一定要先分析自己应用的特性以及目标人群。对别人来说是个好的推广渠道,对你却不一定合适。
用户留存(Retention)
有些应用在解决了活跃度的问题以后,又发现了另一个问题:“用户来得快、走得也快”。有时候我们也说是这款应用没有用户粘性。
解决这个问题首先需要通过日留存率、周留存率、月留存率等指标监控应用的用户流失情况,并采取相应的手段在用户流失之前,激励这些用户继续使用应用。
留存率跟应用的类型也有很大关系。通常来说,工具类应用的首月留存率可能普遍比游戏类的首月留存率要高。
获得收益(Revenue)
获取收入其实是应用运营最核心的一块。收入有很多种来源,主要的有三种:付费应用、应用内付费、以及广告。付费应用在国内的接受程度很低,包括Google Play Store在中国也只推免费应用。在国内,广告是大部分开发者的收入来源,而应用内付费在游戏行业应用比较多。
无论是以上哪一种,收入都直接或间接来自用户。所以,前面所提的提高活跃度、提高留存率,对获取收入来说,是必需的基础。用户基数大了,收入才有可能上量。
推荐传播(Referral)
以前的运营模型到第四个层次就结束了,但是社交网络的兴起,使得运营增加了一个方面,就是基于社交网络的病毒式传播,这已经成为获取用户的一个新途径。这个方式的成本很低,而且效果有可能非常好;唯一的前提是产品自身要足够好,有很好的口碑。
题目二十五:
以下是一家电商网站的一周销售数据,该网站主要用户群是办公室女性,销售额主要集中在5种产品上,如果你是这家公司的分析师
表如下:一组每天某网站的销售数据

a) 销售额在工作日趋于平稳,在2020/9/12、2020/9/13两天下降幅度最大。原因可能是在目标用户群为办公室女性,在周末大家休假的时候他们会选择外出逛街买东西而不是在网络购物
b) 1.增加用户粘度:
1)如在特定的时间发放一定数量的优惠券供目标用户抢,并且设置优惠券使用时间只能是周末使用.
2)利用ABtest,选取一小部分目标用户测试不同风格的对点击量的影响
2.增加平均购物车大小:如设置满减优惠,买够多少可以享受满减,适当设置跨店满减
3.增加病毒式增长系数:设置分享奖励,并且划分奖励层级:新老用户点进分享链接为一级,加入购物车并购买和新用户注册为二级,新用户注册并购买为三级
4.用户调研,了解目标用户周末的行为,询问改进优化方向,完成调查问卷可以设置优惠券等奖励机制
5.挖掘寻找新目标用户,对小部分潜在新群体实行针对他们的MVP测试效果,如果效果良好可以加大规模
方案5来自Acquisition,方案12来自Activation,Retention,方案3来自refer,方案4:用户调研
题目二十六:
下列属于无监督学习的是()
补充:
题目二十七:
用算法拦截可疑笔记,描述拦截的笔记中有多少是真的可疑笔记是()
ROC:所有样本在不同阈值下在 FPR-TPR图中所形成的曲线
AUC:ROC曲线合x坐标轴所围成的面积,(0,1),越接近0模型的预测效果越好
Recall:召回率Recall = FP/(FP+TN)
Precision:精确率,在所有预测预测为正例中属于真的正例的概率。Precision = TP/(TP+FP)
题目二十八:
EXCEL中,“abc1134”位于G3单元格,如何取出它的前3位 ( )
left函数的语法格式: =left(text,num_chars)
text代表用来截取的单元格内容。num_chars代表从左开始截取的字符数。
题目二十九:
某学校男生升学率下降了,女生升学率也下降了,那么总体升学率 ()
题目三十:
关于T检验描述正确的是()
题目三十一:
以下哪些统计方法可以用来分类?()
题目三十二:
下述关于数据库系统错误的说法是()
"空值" 和"NULL"的概念:
1:空值('')是不占用空间的,判断空字符用=''或者<>''来进行处理;
2: NULL值是未知的,且占用空间,不走索引;判断 NULL 用 IS NULL 或者 is not null,SQL语句函数中可以使用ifnull()函数来进行处理.注:在进行count()统计某列的记录数的时候,如果采用的NULL值,会别系统自动忽略掉,但是空值是统计到其中。
记得学习:
辛普森悖论
数据库索引
评价指标
以上就是本篇文章【学习4】的全部内容了,欢迎阅览 ! 文章地址:http://lianchengexpo.xrbh.cn/news/9678.html 资讯 企业新闻 行情 企业黄页 同类资讯 首页 网站地图 返回首页 迅博思语资讯移动站 http://lianchengexpo.xrbh.cn/mobile/ , 查看更多 点击拨打:
点击拨打: